如何從PDF文件中提取原始圖像
介紹
PDF 是最常用的文檔類型之一。在某些情況下,您可能需要 PDF 文件中的圖像,您可以對 PDF 文件進行屏幕截圖以獲取圖像,但使用該方法獲得的不是原始圖像。更糟糕的是,當有大量圖像時,它會花費你很多時間。本教程提供了從 PDF 文件中提取原始圖像的完美解決方案. 無需安裝任何軟件 & 您無需擔心文件的安全性受到威脅.
工具: 提取 PDF 圖像. 現代瀏覽器,如 Chrome、Firefox、Safari、Edge 等。
瀏覽器兼容性
- 支持 FileReader、WebAssembly、HTML5、BLOB、Download 等的瀏覽器。
- 不要被這些要求嚇倒,最近5年的大多數瀏覽器都是兼容的
操作步驟
- 首先打開您的網絡瀏覽器,通過執行以下操作之一,您將看到瀏覽器如下圖所示
- 選項 1: 輸入以下內容 "https://zh-tw.pdf.worthsee.com/pdf-images" 顯示為 #1 在下圖中 或者;
- 選項 2: 輸入以下內容 "https://zh-tw.pdf.worthsee.com", 然後打開 提取 PDF 圖像 工具 通過導航 "PDF工具" => "提取 PDF 圖像"
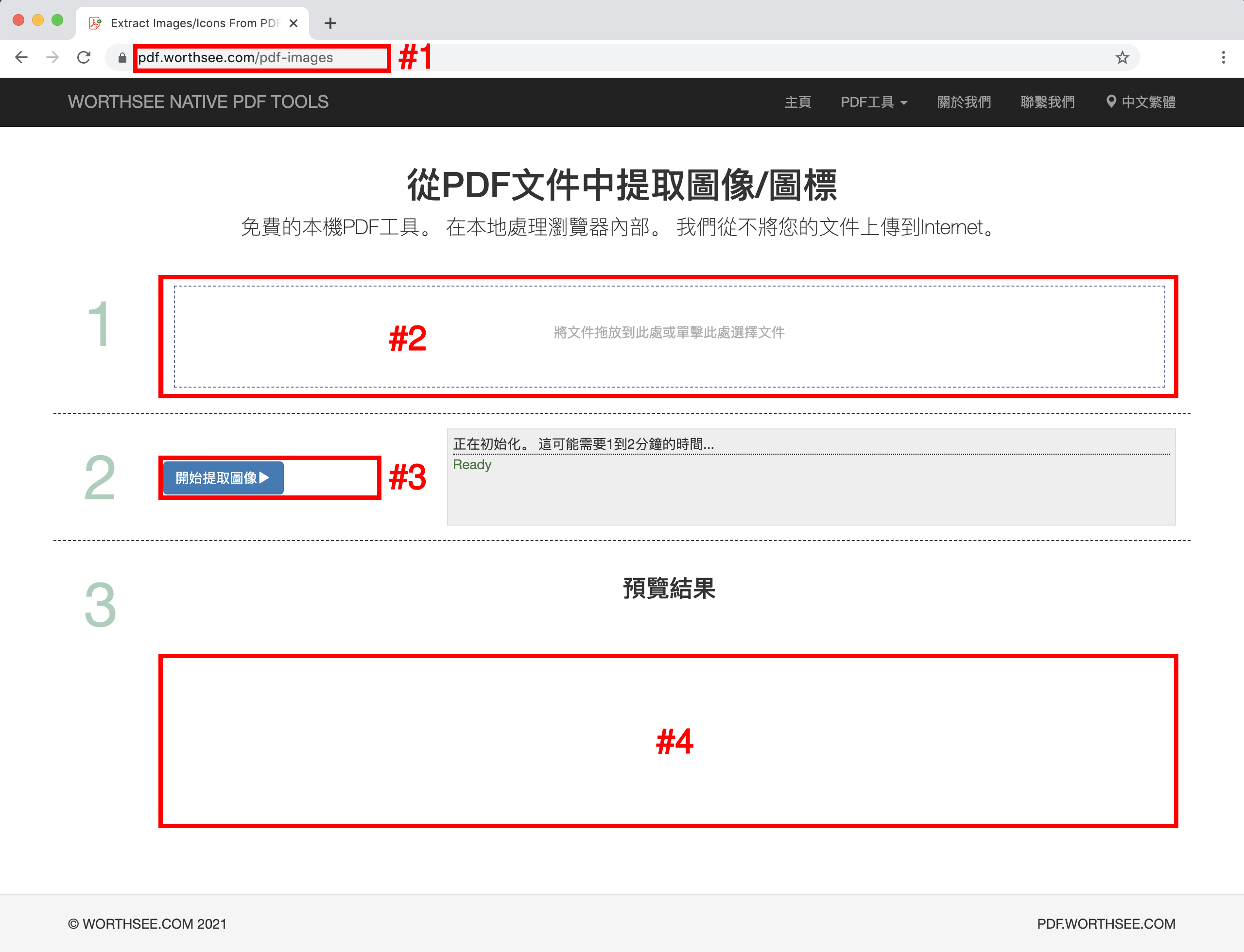
- 點擊 區域 "將文件拖放到此處或單擊此處選擇文件" (顯示為 區域 #2 在上圖中) 選擇PDF文件
- 您還可以將文件拖放到該區域
- 您可以根據需要選擇任意數量的文件,也可以根據需要選擇任意多次。
- 您選擇的文件將顯示在框下 #2 預覽
- 點擊 按鈕 "開始提取圖像" (顯示為 按鈕 #3 在上圖中), 如果文件很大,可能需要一些時間
- 圖像提取完成後,提取的圖像文件將出現在圖像所示的位置 #4 (如上圖所示), 您只需單擊它們即可下載
- 成功處理所選文件後將顯示下載鏈接
- 我們還支持將生成的文件打包為 ZIP 文件。當生成的文件過多時,您可以使用此功能將它們打包成一個 zip 文件,這樣您只需下載一次,而不需要多次點擊下載所有文件